Will AI Replace Your Job?
Explore the impact of artificial intelligence on the future of work, job automation, and how to stay relevant in the age of AI.
Read More →NextAI Labs
AI Research @ NextAI Labs
Subscribe to our newsletter for the latest AI trends and career insights.
AI Research @ NextAI Labs
In the realm of artificial intelligence, communication between humans and machines has always been a challenge. Machines understand numbers, while humans communicate through language, images, and other rich media. This fundamental gap requires a translation layer, and that's precisely what embeddings provide.
Embeddings have become the cornerstone of modern AI systems, from search engines and recommendation systems to large language models like GPT-4 and Claude. They are the invisible force that enables machines to understand semantics, context, and meaning.
In this article, we'll demystify embeddings, explore how they work, and understand why they've revolutionized the field of artificial intelligence. Whether you're a developer looking to implement AI features, a researcher exploring the frontiers of machine learning, or simply a curious mind, this guide will give you a comprehensive understanding of this crucial technology.
At their core, embeddings are dense numerical representations of real-world objects like words, sentences, documents, images, audio clips, or virtually any kind of data. They translate complex information into vectors—ordered lists of numbers—that capture the semantic essence of the original data.
Embedding: A mathematical representation (vector) of an object in a continuous space where similar objects are positioned closer together. Typically, these vectors have hundreds of dimensions, each capturing some aspect of the object's meaning or characteristics.
For example, a word embedding might represent the word "king" as a vector like [0.12, -0.45, 0.32, ...] with anywhere from 100 to 1024 dimensions. This representation is learned from data, allowing the AI to understand that "king" is more similar to "queen" than to "bicycle" based on the mathematical distance between their respective vectors.
Embeddings serve as the foundation for many AI tasks because they translate the messy, complex world into a mathematical space that machines can work with—a space where semantic relationships become geometric relationships.

Embeddings have fundamentally transformed how AI systems understand and process information. Here's why they're so important:
Traditional methods like one-hot encoding treat all words as equally different from each other. Embeddings, however, capture meaningful relationships. In embedding space, "dog" and "cat" would be closer together than "dog" and "refrigerator" because they share semantic qualities.
Embeddings support mathematical operations that yield meaningful results. The classic example is the vector operation: "king" - "man" + "woman" ≈ "queen". This ability to perform "word algebra" demonstrates how embeddings capture semantic relationships.
Language has millions of words, and representing each as a separate dimension would be computationally infeasible. Embeddings compress this information into dense vectors (typically 100-1024 dimensions), making computations more efficient while retaining semantic information.
Pre-trained embeddings allow AI systems to transfer knowledge from one task to another. Models like BERT and GPT generate contextual embeddings that capture deep linguistic patterns, which can then be fine-tuned for specific applications.
Vector Space: In embedding space, similarity is often measured by cosine similarity or Euclidean distance. Cosine similarity measures the angle between vectors, while Euclidean distance measures the straight-line distance between them.
Creating embeddings involves training neural networks on large amounts of data to learn meaningful representations. Let's explore the most common approaches:
Developed by researchers at Google in 2013, Word2Vec revolutionized NLP by creating word embeddings based on the distributional hypothesis: words that appear in similar contexts tend to have similar meanings. Word2Vec uses two approaches:
Python - Word2Vec Examplefrom gensim.models import Word2Vec # Sample sentences sentences = [ ["cat", "eat", "food"], ["dog", "chase", "cat"], ["man", "feed", "dog", "and", "cat"] ] # Train Word2Vec model model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4) # Get vector for 'cat' cat_vector = model.wv['cat'] # Find words most similar to 'cat' similar_words = model.wv.most_similar('cat') print(similar_words)
Traditional word embeddings assign the same vector to a word regardless of context. More advanced models like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer) generate contextual embeddings that change based on how a word is used in a sentence.
For example, in contextual embeddings, the word "bank" would have different representations in "river bank" and "bank account," capturing the word's meaning in context.
Python - BERT Embeddings Examplefrom transformers import AutoTokenizer, AutoModel import torch # Load pre-trained model and tokenizer tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased") model = AutoModel.from_pretrained("bert-base-uncased") # Tokenize sentences sentences = ["The bank by the river is eroding.", "I need to deposit money at the bank."] inputs = tokenizer(sentences, padding=True, truncation=True, return_tensors="pt") # Get contextual embeddings with torch.no_grad(): outputs = model(**inputs) # Extract embeddings from last hidden state embeddings = outputs.last_hidden_state # Get embeddings for the word "bank" in both sentences # Note: We need to find the token index for "bank" in each sentence print(f"Embedding dimensions: {embeddings.shape}") # [2, sequence_length, 768]
Embeddings aren't limited to text. Models like CLIP (Contrastive Language-Image Pre-training) by OpenAI create embeddings for both images and text in a shared vector space, allowing for cross-modal understanding.
Attention Mechanisms: Modern embedding models like BERT and GPT use self-attention mechanisms to weigh the importance of different words in context, allowing for more nuanced representations of language.
Embeddings power many AI applications we use daily:
Modern search engines use embeddings to understand the semantic intent behind queries, not just matching keywords. This enables them to return relevant results even when the query uses different terminology than the documents.
Streaming services, e-commerce platforms, and social media networks use embeddings to represent users and items in the same vector space. Recommendations are generated by finding items whose embeddings are closest to a user's preferences.
Neural machine translation models create embeddings of source language sentences and decode them into target languages, capturing subtle linguistic nuances better than previous approaches.
Large language models use embeddings to retrieve relevant information from knowledge bases before generating responses, improving factuality and reducing hallucinations.
Python - RAG System Examplefrom sentence_transformers import SentenceTransformer import numpy as np # Load pre-trained embedding model model = SentenceTransformer('all-MiniLM-L6-v2') # Sample knowledge base documents = [ "The Eiffel Tower is located in Paris, France.", "The Great Wall of China is over 13,000 miles long.", "The Mona Lisa was painted by Leonardo da Vinci." ] # Generate embeddings for documents document_embeddings = model.encode(documents) # Function to retrieve relevant document given a query def retrieve(query, top_k=1): # Generate embedding for the query query_embedding = model.encode([query])[0] # Calculate similarity similarities = np.dot(document_embeddings, query_embedding) / \ (np.linalg.norm(document_embeddings, axis=1) * np.linalg.norm(query_embedding)) # Get top-k most similar documents top_indices = np.argsort(similarities)[-top_k:][::-1] return [documents[i] for i in top_indices] # Example query query = "Who created the famous painting of a woman with a mysterious smile?" relevant_docs = retrieve(query) print(f"Query: {query}") print(f"Retrieved document: {relevant_docs[0]}")
There are several approaches to generating embeddings for your applications:
The simplest approach is to leverage existing models like:
For domain-specific tasks, fine-tuning pre-trained embeddings on your data often yields better results. This process adjusts the embeddings to better capture the relationships specific to your domain.
If you have unique requirements or sufficient domain data, training custom embeddings from scratch is an option, though it requires more computational resources and expertise.
Python - Fine-tuning Embeddingsfrom sentence_transformers import SentenceTransformer, InputExample, losses from torch.utils.data import DataLoader # Sample training data (pairs of similar sentences) train_examples = [ InputExample(texts=['The patient shows symptoms of fever', 'The client has an elevated temperature'], label=1.0), # These should be similar InputExample(texts=['Administer medication as prescribed', 'Take medicine according to doctor instructions'], label=0.9), # Add more domain-specific examples ] # Create a DataLoader train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16) # Load pre-trained model model = SentenceTransformer('all-MiniLM-L6-v2') # Define loss function train_loss = losses.CosineSimilarityLoss(model) # Train the model model.fit( train_objectives=[(train_dataloader, train_loss)], epochs=4, warmup_steps=100, output_path="fine-tuned-embeddings-medical" )
While embeddings have revolutionized AI, they come with certain challenges:
Embeddings trained on human-generated text inherit and can amplify biases present in the training data. For example, word embeddings have been shown to associate certain professions with specific genders or ethnicities, reflecting societal biases in the training corpus.
Debiasing Techniques: Methods like Bolukbasi's algorithm attempt to identify and remove bias directions in embedding spaces, though complete removal of bias remains an open challenge.
Even contextual embedding models struggle with disambiguating highly polysemous words or understanding complex metaphors and idioms.
Creating aligned embedding spaces across languages remains challenging, especially for low-resource languages or languages with very different structures.
Training and storing embeddings, especially for large vocabularies or datasets, can require significant computational resources and memory.
The field of embeddings continues to evolve rapidly, with several exciting directions:
Future models will create unified embedding spaces across text, images, audio, video, and even 3D environments, enabling more sophisticated cross-modal reasoning.
Next-generation embeddings will adapt in real-time to user behavior and context, providing more personalized and accurate representations.
Research in distillation, quantization, and sparse representations aims to create embeddings that require fewer computational resources without sacrificing quality.
Advances in self-supervised learning will enable models to learn more meaningful embeddings from unlabeled data, reducing the need for expensive annotations.
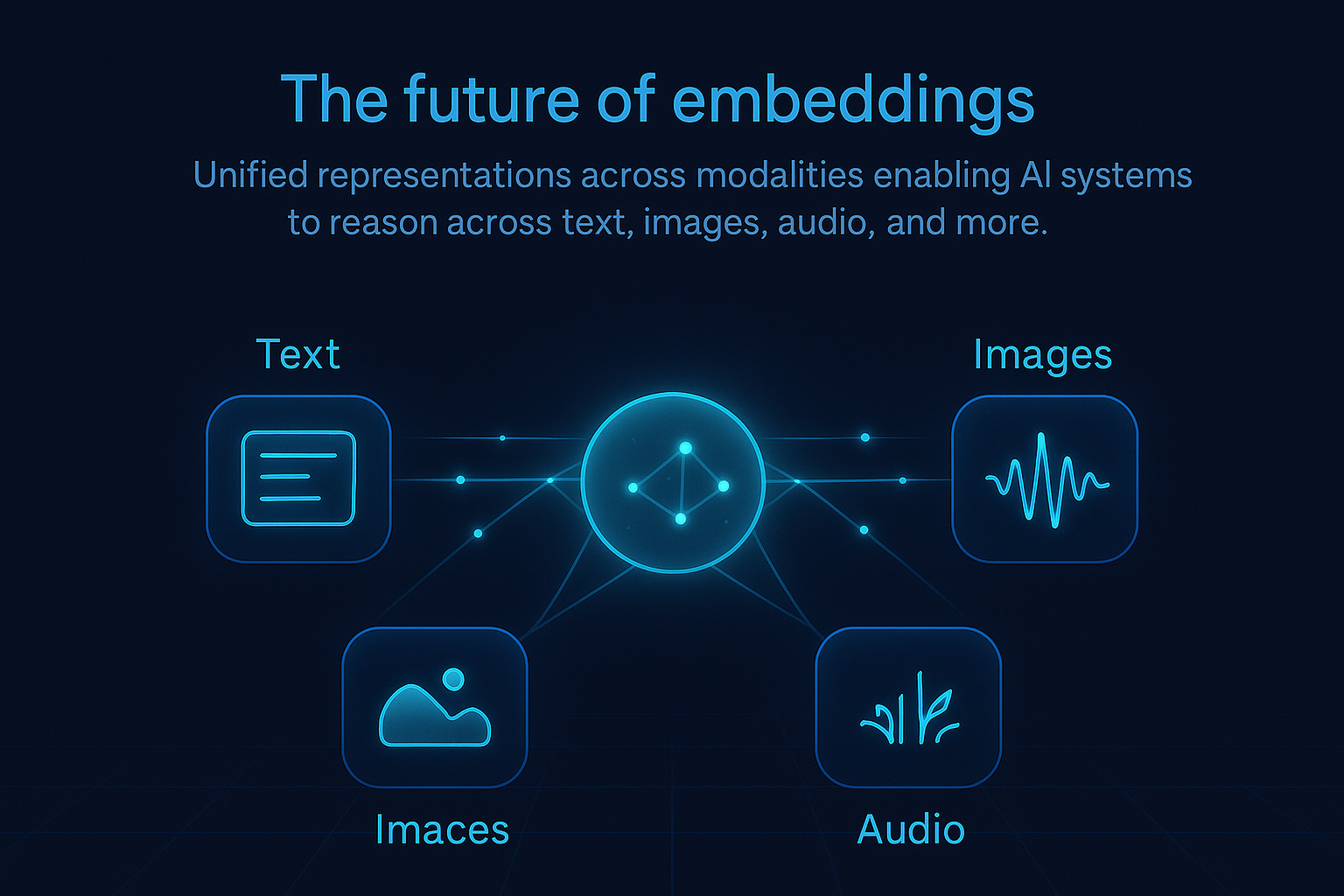
Embeddings have become the universal language through which AI systems understand and process the world. By transforming complex, unstructured data into mathematical representations that preserve semantic relationships, they enable machines to reason about language, images, and other modalities in ways that increasingly resemble human understanding.
As embedding techniques continue to evolve, they will unlock even more powerful AI capabilities, making systems more intuitive, efficient, and capable of understanding the rich, multimodal world we inhabit. Whether you're building the next generation of AI applications or simply interested in how these systems work, understanding embeddings is essential to navigating the future of technology.
NextAI Labs is at the forefront of AI research, specializing in natural language processing and multimodal learning. With a team of experts in computational linguistics and machine learning, we contribute to several open-source projects and publish papers on efficient representation learning. When not exploring the frontiers of AI, our team enjoys hiking and playing the piano.
Explore the impact of artificial intelligence on the future of work, job automation, and how to stay relevant in the age of AI.
Read More →Join thousands of professionals learning cutting-edge AI skills with our specialized courses.